I work in ads measurement. Which means I spend a lot of time explaining, diplomatically, that the number a marketer is looking at does not mean what they think it means.
The number is usually some form of attributed conversions. Someone saw your ad, later clicked it, later bought something, and the platform gave you credit. Seems reasonable. The problem is that a lot of those people were going to buy anyway. The ad did not cause the purchase. It just happened to be nearby when the purchase occurred.
This is the attribution problem, and it has been known for at least fifteen years. What has been harder to fix is the scale problem: the only clean way to measure whether an ad actually caused a purchase is to run a randomised controlled trial, withholding the ad from a random group of users and comparing outcomes. RCTs work. They are also expensive, operationally complex, and most advertisers run them on a fraction of their campaigns.
So the industry defaulted to a shortcut: last-click attribution. Credit the conversion to whichever ad was clicked most recently before the purchase. Easy to compute. Directionally useful. And, according to a new paper from Meta Research and Northwestern, wrong in a way that systematically misleads advertisers about what is working.
The paper is called Predicted Incrementality by Experimentation, or PIE. It uses 2,226 real ad experiments run on Meta to put a number on just how wrong.
The gap is not small
The cleanest way to see the problem is to compare both methods against ground truth, which in this case is the actual RCT result. How well does each method predict the true causal effect of an ad campaign?
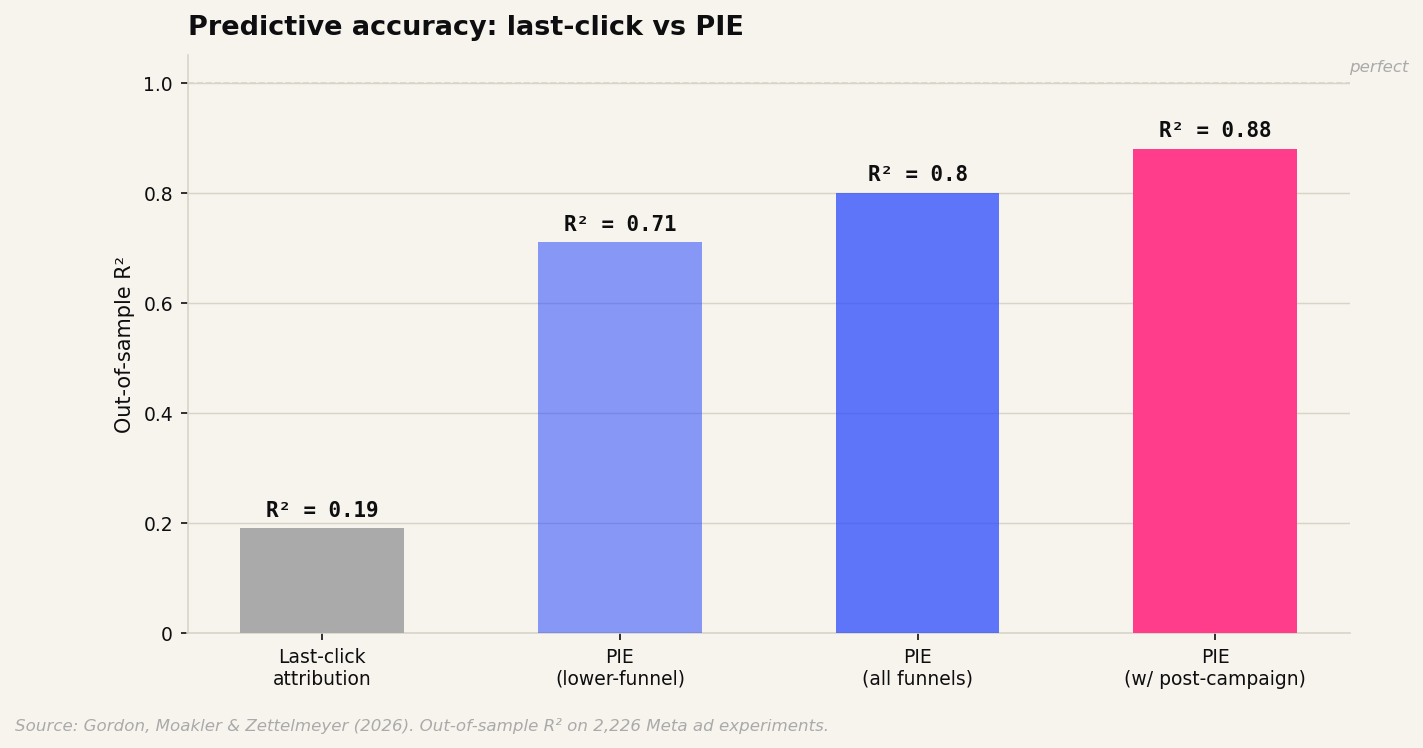
Last-click attribution, applied directly as a proxy for causal effect, achieves an out-of-sample R² of 0.19. That means it explains about 19% of the variance in actual ad effectiveness. The remaining 81% is noise, bias, or both.
PIE, trained on the same RCT data and applied to campaigns that never ran an experiment, achieves an out-of-sample R² of 0.88.
That is not a marginal improvement. That is the difference between a measurement system and a guess with a spreadsheet attached.
What PIE actually does
The insight behind PIE is a reframe. Rather than asking "what caused this conversion?" (a causal question, hard to answer without an experiment), PIE asks "given everything I know about this campaign, what would an experiment have found?" (a prediction question, which machine learning is well suited to).
Here is how it works in three steps.
First, run RCTs on a sample of campaigns. This gives you ground truth causal effects for those campaigns. Second, train a model on that sample, mapping campaign features to causal effects. The features include obvious things like campaign objective, industry vertical, and budget, but also post-campaign data like click-through rates and last-click conversions. Crucially, these post-campaign features are not used as causal estimates. They are used as signals that correlate with true incrementality, because the campaigns that generate lots of clicks tend to be the campaigns that also move the needle.
Third, apply the model to campaigns that never ran an RCT. You now have a predicted causal effect for every campaign, not just the ones you could afford to experiment on.
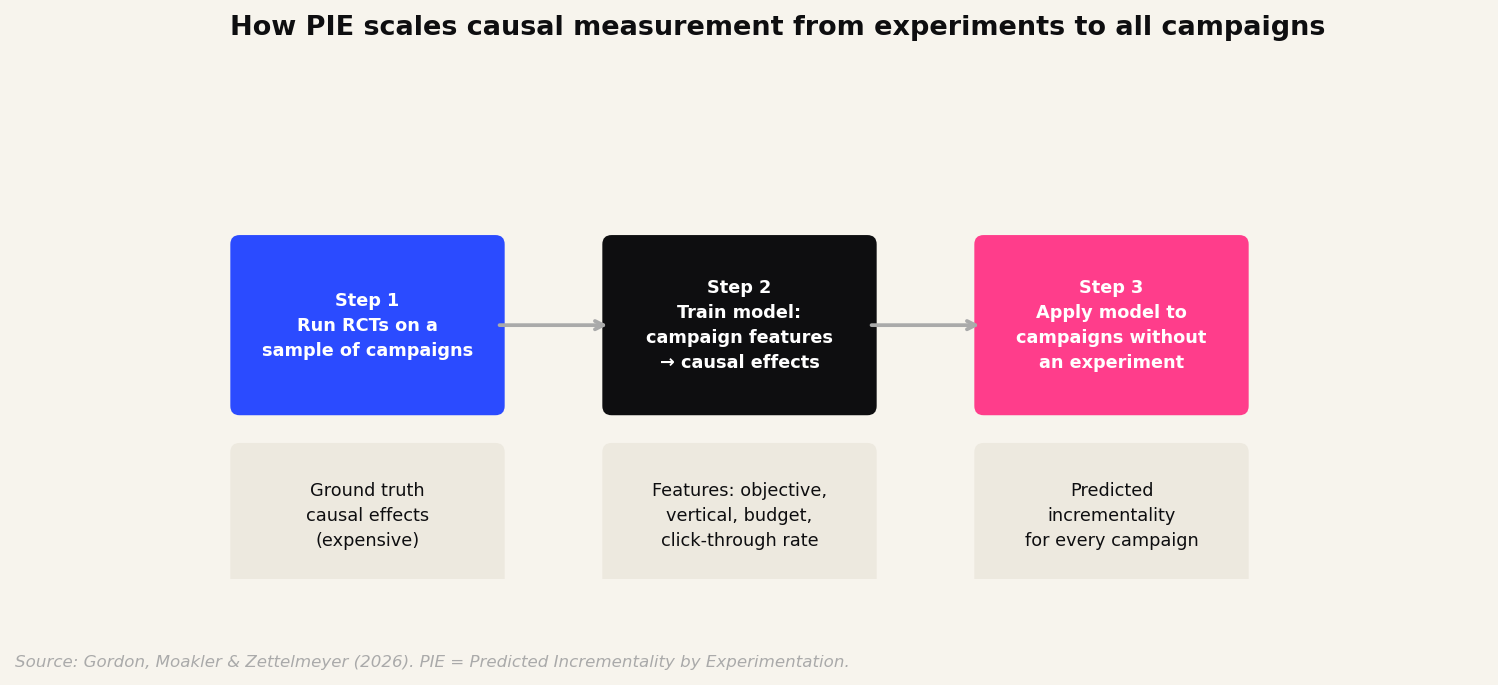
The key distinction, and the thing that makes this work, is that PIE treats measurement as a prediction problem, not an identification problem. Once the RCTs have done the hard causal work, everything else is pattern recognition. That is a fundamentally more tractable task.
Where last-click goes wrong
Last-click does not just add noise. It adds noise in a specific direction.
The paper finds that last-click attribution is systematically upwardly biased. It overcounts conversions by capturing purchases that happened up to seven days after an ad click, regardless of whether the ad was the reason for the purchase. The result is a metric that almost never calls a genuinely successful campaign unsuccessful (low false negatives), but frequently calls an unsuccessful campaign successful (high false positives).
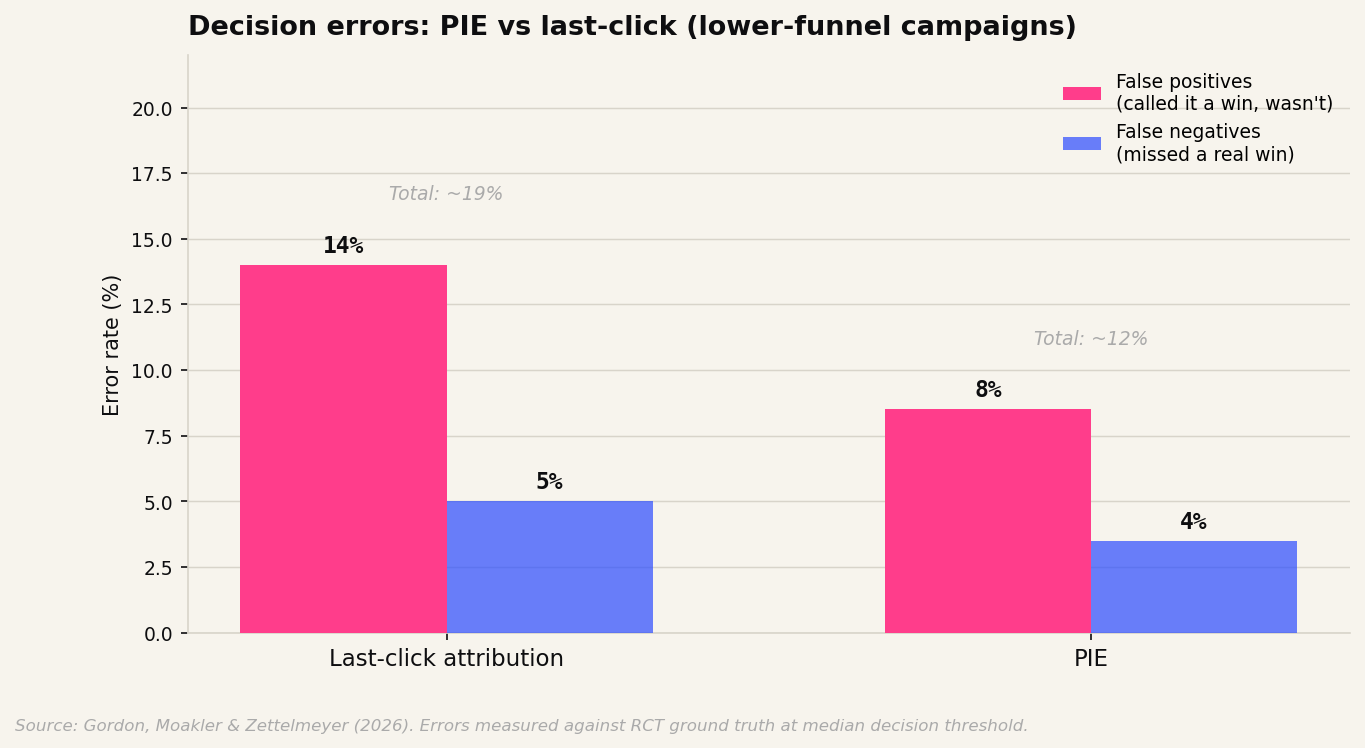
In plain terms: if you rely on last-click, you will rarely miss a campaign that worked. But you will regularly convince yourself that a campaign worked when it did not. That is the expensive error. It is the one that causes you to double down on spend that is not doing anything.
PIE achieves lower and more balanced error rates on both sides. At the median decision threshold, last-click disagrees with the RCT ground truth in about 19% of lower-funnel campaigns. PIE reduces that to 12%.
One in five versus roughly one in eight. Across the scale of a real ad budget, that is a lot of money chasing the wrong campaigns.
Why this matters beyond Meta
The paper is built on Meta data, and the authors are careful to note that some findings may not generalise directly to other platforms, particularly search advertising where selection bias operates differently. On search, users who see ads have already expressed intent through their query, which makes attribution even harder to untangle.
But the core problem, that last-click cannot distinguish between an ad that caused a purchase and an ad that witnessed one, is universal. Every platform that uses click-based attribution has this problem. The RCT-then-predict approach that PIE uses could in principle be applied anywhere that has a sufficient base of past experiments to train on.
The practical barrier is that most advertisers have not run 2,226 experiments. Meta has. And the paper shows that PIE's performance scales reasonably with training sample size: you do not need thousands of RCTs to get useful predictions, though more is better.
The measurement scientist's read
I want to be honest about what this paper is and is not saying.
It is not saying that last-click attribution is useless. For a quick directional signal, for monitoring relative performance across campaigns, it retains some value. The R² of 0.19 is not zero.
It is saying that last-click attribution is not a measurement of causal effect. If you are using it to answer the question "did this ad work?", you are using the wrong tool. The error rate is not random, it skews in a specific direction (optimistic), and the cost of systematic false positives is real budget misallocation compounded over time.
The deeper point is about what it takes to fix this. PIE requires a platform that has run enough RCTs to train on. That gives large platforms with existing experimentation infrastructure a structural advantage in measurement quality. Advertisers who run on those platforms get better measurement almost as a byproduct.
Smaller platforms, and advertisers who run primarily on platforms without a deep experiment base, face a harder problem. The shortcut is not just imprecise for them. It may be the only option available.
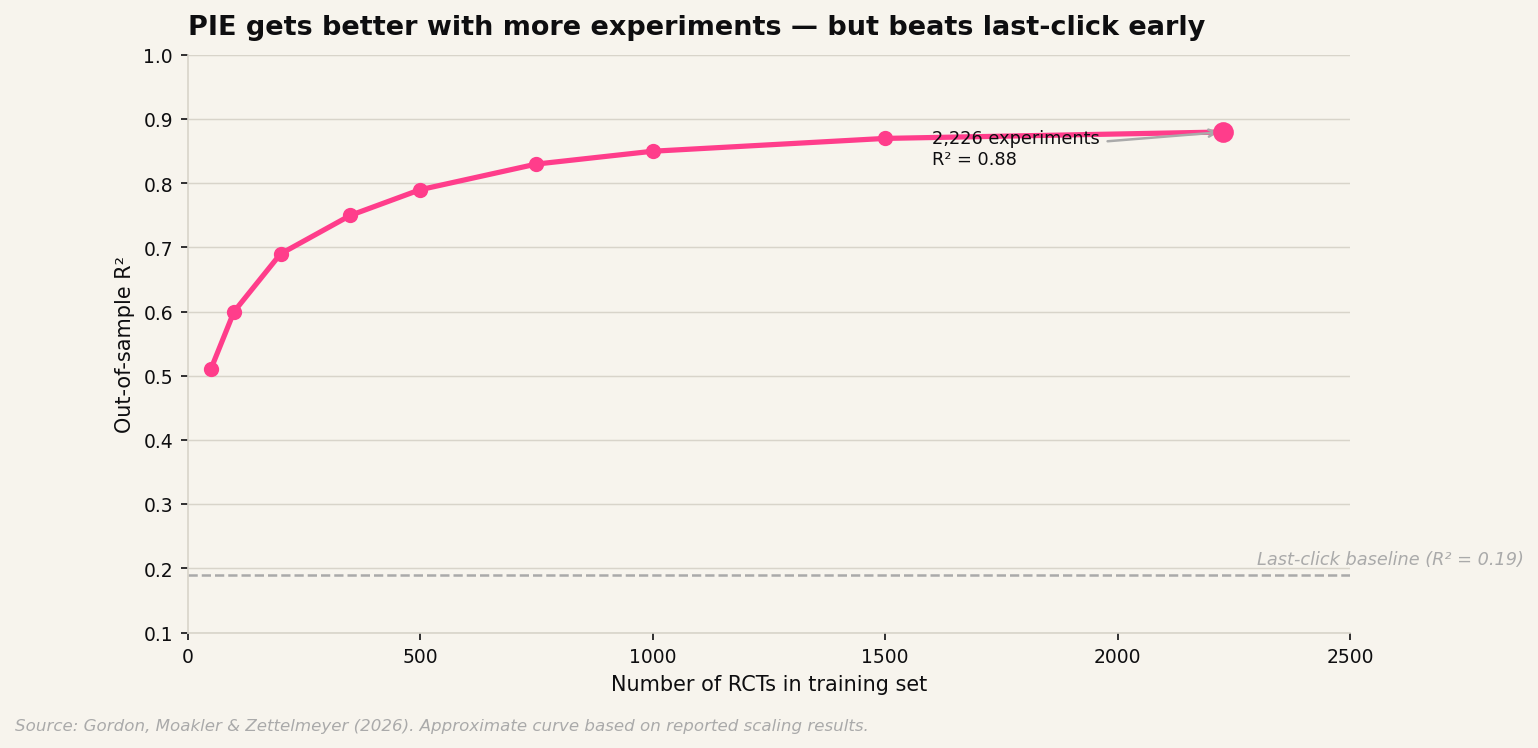
The paper is also, implicitly, an argument for running more RCTs. Every experiment you run makes the prediction model better, not just for you, but for everyone on the platform whose campaigns share similar features. Experimentation, at scale, becomes a public good.
That is the measurement problem stated as clearly as I know how to state it. The number on your dashboard is an estimate. PIE is a better estimate. The ground truth is the experiment. Everything else is approximation, and the question is how good an approximation you can afford.
Source: Gordon, Moakler, and Zettelmeyer, "Predicted Incrementality by Experimentation (PIE) for Ad Measurement," March 2026. Dataset: 2,226 Meta ad experiments across e-commerce, retail, and travel verticals.